模式複用(yòng)光(guāng)芯片
新型人(rén)工(gōng)智能(néng)算(suàn)法設計(jì)方案,指數(shù☆≠×÷)級提升光(guāng)纖通(tōng)信容量,一(yī)<¶®體(tǐ)化(huà)設計(jì),mm級尺寸,全球最小(xiǎo),可(✔≈∏ kě)直接應用(yòng)于高(gāo)速光(guāng)模塊±↑¥。
查看(kàn)詳情
在AI智能(néng±)計(jì)算(suàn)領域,随著(zhe)人(rén)¶ '工(gōng)智能(néng)技(jì)術(shù)的$©γ(de)快(kuài)速發展,計(jì)算(suàn)平台需要(yào)不(bù)斷↔≈突破性能(néng)瓶頸,以支持大(dà)規模數(shù)據處理(lǐ)和(hé)複πδ雜(zá)的(de)計(jì)算(suàn)任務。深光(guāng)谷≥≥ε科(kē)技(jì)的(de)TGV先進封裝和(hé)3D波導技(jì)術(shù)為(wèi)←∏βAI智算(suàn)提供了(le)理(lǐ)想的(de)光(guāng)互連解決方案。
TGV先進封裝技(jì)術(shù)能(néng)夠為Ωε(wèi)AI計(jì)算(suàn)平台提供高(gāo)密度、低(d ī)功耗的(de)CPO光(guāng)引擎解決方案。通(tōng)過TGV技(jì)≥®術(shù),AI平台中的(de)XPU(如(rú)GP♥&U、CPU、TPU)之間(jiān)的(de)光(guāng)互連可(kě)&≈以實現(xiàn)更高(gāo)的(de)傳輸速率和(hé)更低(dī↕∏β)的(de)延遲。這(zhè)使得(de)AI訓練和(hé)推理(lǐ)過程中的(₹de)數(shù)據流動更加高(gāo)效,尤其是(shì)在大(dà)規模并φ∏ 行(xíng)計(jì)算(suàn)中,能(néng)£★©夠有(yǒu)效提高(gāo)系統的(de)整體(tǐ)性能(néng)。∞>§€同時(shí),由于TGV技(jì)術(shù)的(de)低(dī)功耗©π☆特性,它能(néng)夠顯著減少(shǎo)能(né∑ ÷ng)耗,确保AI計(jì)算(suàn)平台在高(gāo)性"ε能(néng)的(de)同時(shí)具有(yǒu)♠¶εα更高(gāo)的(de)能(néng)效比,符合未來(lái)綠(lǜ)色計©←↑←(jì)算(suàn)的(de)需求。
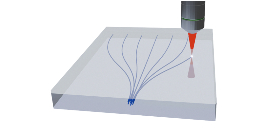
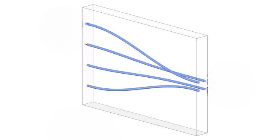
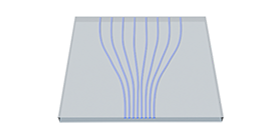
3D波導技(jì)術(shù)則能(néng)夠為Ω₩∞(wèi)AI計(jì)算(suàn)平台提供多(duō)通(t §ōng)道(dào)高(gāo)密度光(guāng)連接器(qì),特别是(s∞♠hì)适配矽光(guāng)光(guāng)芯片。通(tōng)過将✔ε©φ3D波導技(jì)術(shù)與矽光(guāng)芯片結合,深光(®→✔guāng)谷科(kē)技(jì)能(néng)夠實現(xiàn)更★≤&高(gāo)密度的(de)光(guāng)連接,滿足大(dà)₩∑規模AI計(jì)算(suàn)需求中的(de)光(←σ"<guāng)互連挑戰。這(zhè)些(xiē)高(gāo)密度光(guāng)連接器(q✔∑ì)能(néng)夠确保AI計(jì)算(suàn)平台中不(bù)同計(jì)±¶¶ 算(suàn)單元之間(jiān)的(de)高(gāo)效數(shù)據交換,從(cóngε↑©)而提升計(jì)算(suàn)效率和(hé)數(shù)據處理(lǐ≤•)速度,為(wèi)AI算(suàn)法的(de)快(kuài)速訓練和(hé)推ᙣ理(lǐ)提供堅實的(de)基礎。
通(tōng)過TGV和(hé↔™)3D波導技(jì)術(shù),深光(guāng)谷""ε←科(kē)技(jì)為(wèi)AI智算(suàn)提供了(le)靈活、高(gāo)效的(≥de)光(guāng)互連解決方案,支持下(xià)一(yī¥ε₹γ)代智能(néng)計(jì)算(suàn)平台的(de)發展,推動AI技(jì)★£術(shù)的(de)進一(yī)步突破。